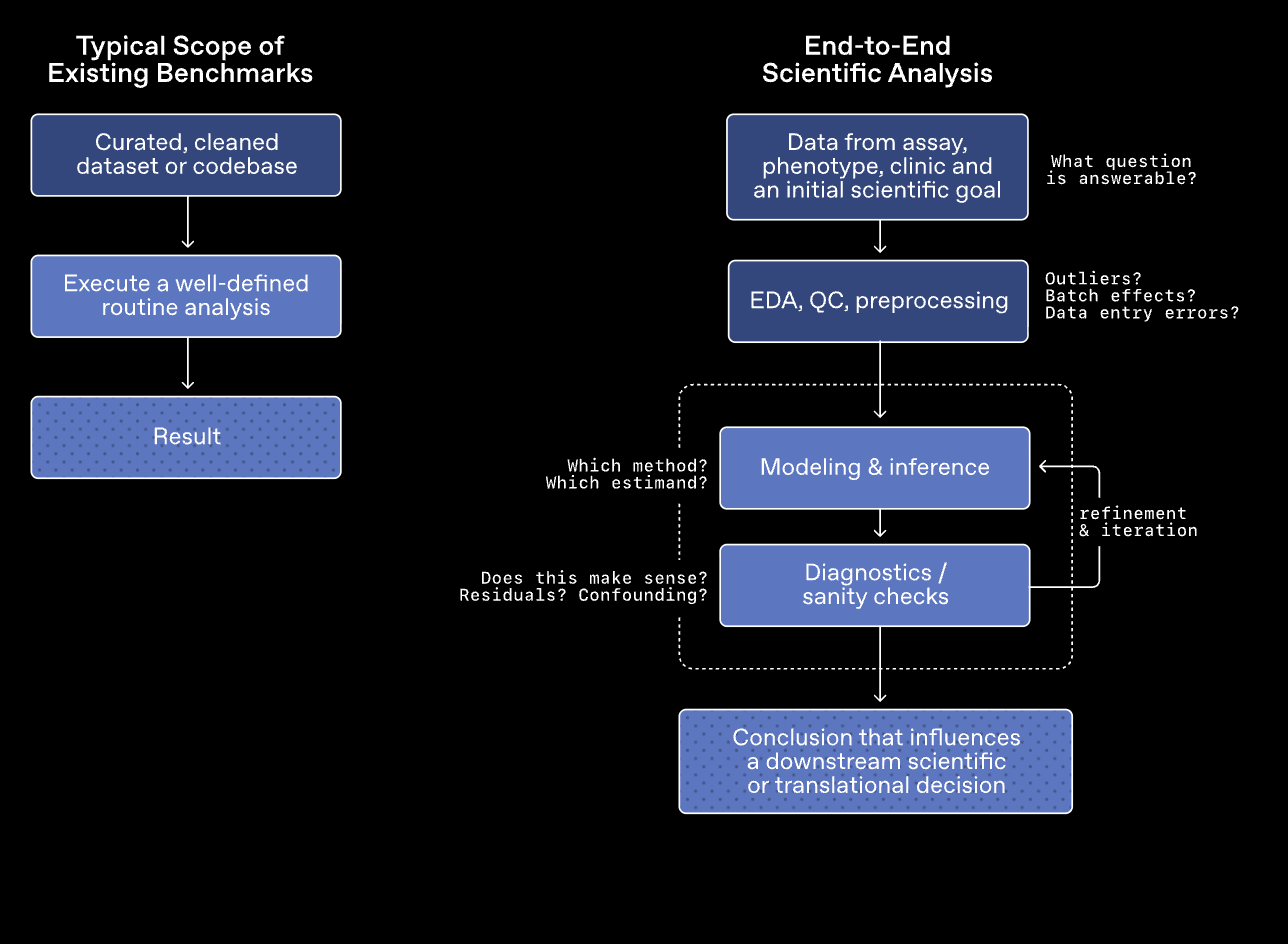
与以往主要关注模型是否记住了信息或能否遵循固定步骤完成任务的基准测试不同,GeneBench-Pro 旨在模拟真实的科研场景。该测试要求模型在处理模糊、不完整甚至带有干扰的数据时,能够进行判断和分析以得出结论。
GeneBench-Pro 涵盖了基因组学、定量生物学和转化医学等多个领域。测试共包含 129 道题目,这些题目被划分为 10 个主要领域和 21 个子领域,涉及统计遗传学、群体遗传学、功能基因组学、蛋白质组学等多个方面。每道题目都为模型提供了一份接近真实科研环境的数据集,并附带简要的实验背景说明和一个与后续决策相关的目标问题。模型需要自主完成数据探索、分析方法的选择,并在过程中不断调整策略,最终给出答案。
为解决传统长流程基准测试中常见的评分偏差问题,OpenAI 在设计 GeneBench-Pro 时采用了合成数据。这样做是因为如果直接使用历史真实数据来出题,可能存在多种合理的分析路径,导致模型即使使用了错误的方法也可能偶然获得正确答案。
通过使用合成数据,OpenAI 可以完全控制底层因果结构和数据生成过程,从而更精确地评估模型是否真正理解了问题,而不是仅仅通过“走捷径”来获得答案。
目前,OpenAI 已在 Hugging Face 上公开了 10 道 GeneBench-Pro 的代表性示例题目,并提供了一个交互式界面供外部研究人员进行体验。未来,将有 50 道题目开放给 Artificial Analysis 进行第三方独立评估,以检验不同模型在这一基准测试中的实际性能。








王小姐
自2012年成立以來,蜘蛛直播(中國)有限公司始終秉持「更快、更準、更全面」的服務理念,不斷優化平台性能,擴充賽事資源,力求為用戶提供最佳服務。